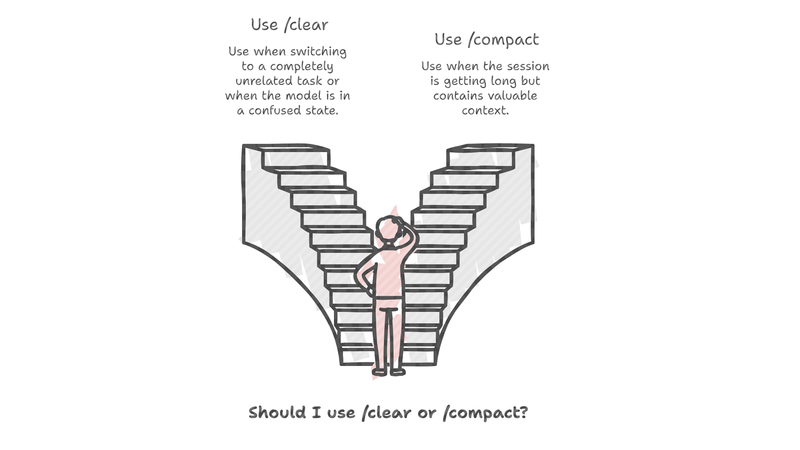
A question that comes up constantly in Claude Code enablement conversations: why bother with context hygiene at all? Session getting long, model acting strange, output drifting? Just blow it up. Hit /clear, start fresh, move on. It is a reasonable…
Why /compact Should Be Your Default (and /clear Your Last Resort)