
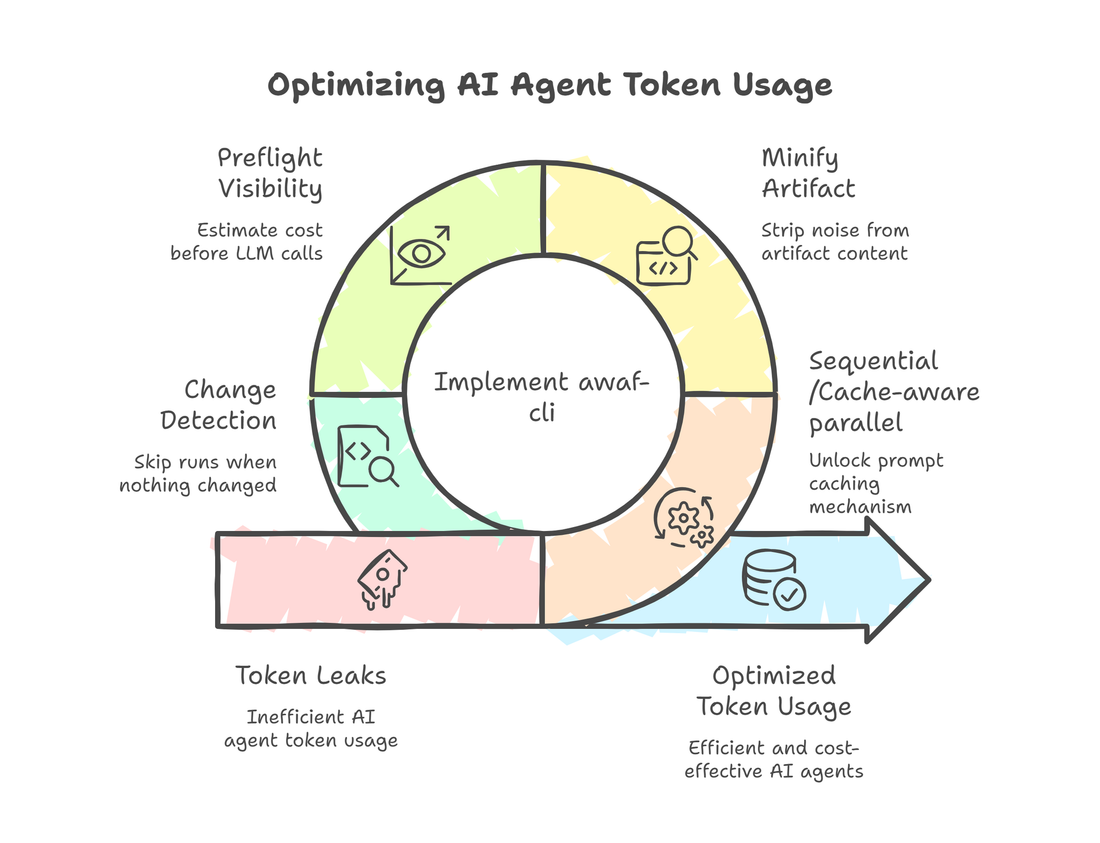
How I cut multi-agent LLM costs by 70% using prompt caching, artifact minification, and smarter execution order — and what the AWAF assessment found along the way.
Your AI Agents Are Leaking Tokens, Are You Aware?

My name is Yogi Aradhye. I'm a software engineer, author and speaker based in Austin, TX. It's nice to meet you.
How I cut multi-agent LLM costs by 70% using prompt caching, artifact minification, and smarter execution order — and what the AWAF assessment found along the way.
I built an agentic system to help anyone feeling the labor market shift think clearly about what comes next. Then I scored it against my own framework. It got a 52
Every team is bolting agentic AI onto everything right now. It's giving pure Agent Smith energy. And we're about to pay the same price we paid with microservices unless we build a framework to stop it.

Agent talk is everywhere. In client meetings and hallway conversations, the theme keeps coming up. Social media can make it feel like agents will soon be serving your next coffee. Maybe one day. Today, we are not there yet. Over the last few months, I have been experimenting heavily on…

As a development team, our goal is to deliver software that solves business problems. The business’ goal is to provide value to the customers as quickly as possible. “Monolith to microservices” is not a business goal. Business stakeholders don't care about architecture choices. They care if their customers…
In a previous post [https://aradhye.com/how-integration-patterns-impact-your-microservices-architecture/] on microservices integration patterns, we talked briefly about messaging. Messaging comes with many options and patterns, and one of the most critical decisions you’ll make is choosing between message brokers. RabbitMQ and Kafka are lead…
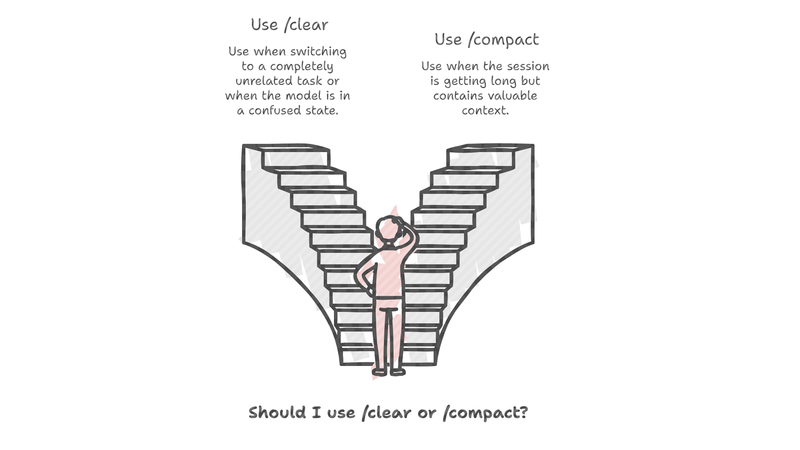
A question that comes up constantly in Claude Code enablement conversations: why bother with context hygiene at all? Session getting long, model acting strange, output drifting? Just blow it up. Hit /clear, start fresh, move on. It is a reasonable…
Hyperscaler AI platforms solved a problem that no longer exists. When Claude writes your dashboard in 20 minutes and your agent infrastructure in an afternoon, the platform tax stops being pragmatic and starts being deadweight.

Are you familiar with the Well-Architected Framework (WAF)? It's an essential tool for ensuring that your cloud computing infrastructure is secure, efficient, reliable, and cost-effective. Neglecting to use of the WAF can result in a range…
In part 1 of our microservices readiness series [https://aradhye.com/are-you-ready-for-microservices-pt-1-need-alternatives-and-ability/] , we looked at how we determine if microservices is actually the right route for you. Once you’ve…

Cloud adoption is happening at a rapid pace these days. With a global pandemic raging, the cloud is only gaining more steam. Disasters always drive home the urgency of readiness and responsiveness. One of our clients experienced this firsthand during…