
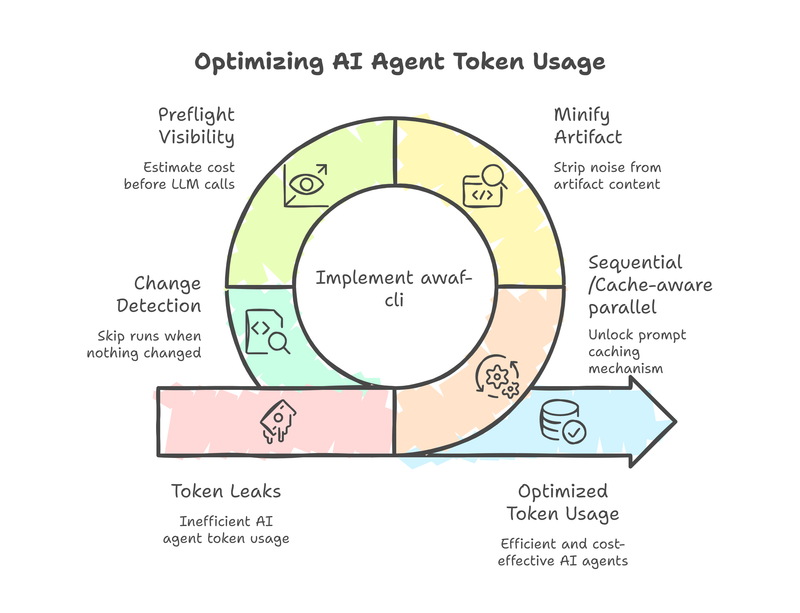
How I cut multi-agent LLM costs by 70% using prompt caching, artifact minification, and smarter execution order — and what the AWAF assessment found along the way.
Your AI Agents Are Leaking Tokens, Are You Aware?
A collection of 1 post
How I cut multi-agent LLM costs by 70% using prompt caching, artifact minification, and smarter execution order — and what the AWAF assessment found along the way.