
Memory leaks killed applications before profilers existed. Nobody noticed until the server ran out of memory at 2am. Token leaks are doing the same thing to AI budgets right now: quietly, invisibly, at every request.
A token leak is not a crash. The agents run. The responses come back. The logs look fine. And that is the dangerous part: agents fail but they sound right. The output is plausible, the pipeline completes, and somewhere in the background tokens are being sent that do not need to be sent, calls are being made that could be skipped, and context is being rebuilt from scratch that was already paid for. It adds up fast and nothing alerts you.
I found one in my own system. Here is what it looked like, how I caught it, and what the fixes did to the score.
Why I built awaf-cli
Your agentic system is in production. Users are hitting it. Something feels off but you cannot tell what. Maybe costs are spiking. Maybe a pipeline that was supposed to check a human approval gate is just not doing that anymore. You read the code. Nothing obvious jumps out.
What you do not have is a structured way to ask: is this system actually well-architected? Not "does it work" but "is it built in a way that will hold up?"
That is the gap AWAF fills. awaf-cli scores your codebase across 10 architectural pillars: Foundation, Security, Reliability, Controllability, Context Integrity, and five more. Each finding cites the specific file and line. Not "consider adding a circuit breaker." The exact line where the circuit breaker should be and why it matters.
The latest full Sonnet report on glitched.sh is available as a gist: 29 High findings across 10 pillars, each with file, line, and root cause. That depth is the point. It is also what drove the token problem this post is actually about.
awaf-cli is not agentic. That is the point.
Look at this quadrant. Agents sit top-right: multi-step, adaptive, tool use, real-time decisions. awaf-cli sits top-left: fixed sequence, 10 LLM calls in a defined order, no runtime decisions, fully deterministic. It is a workflow, not an agent.
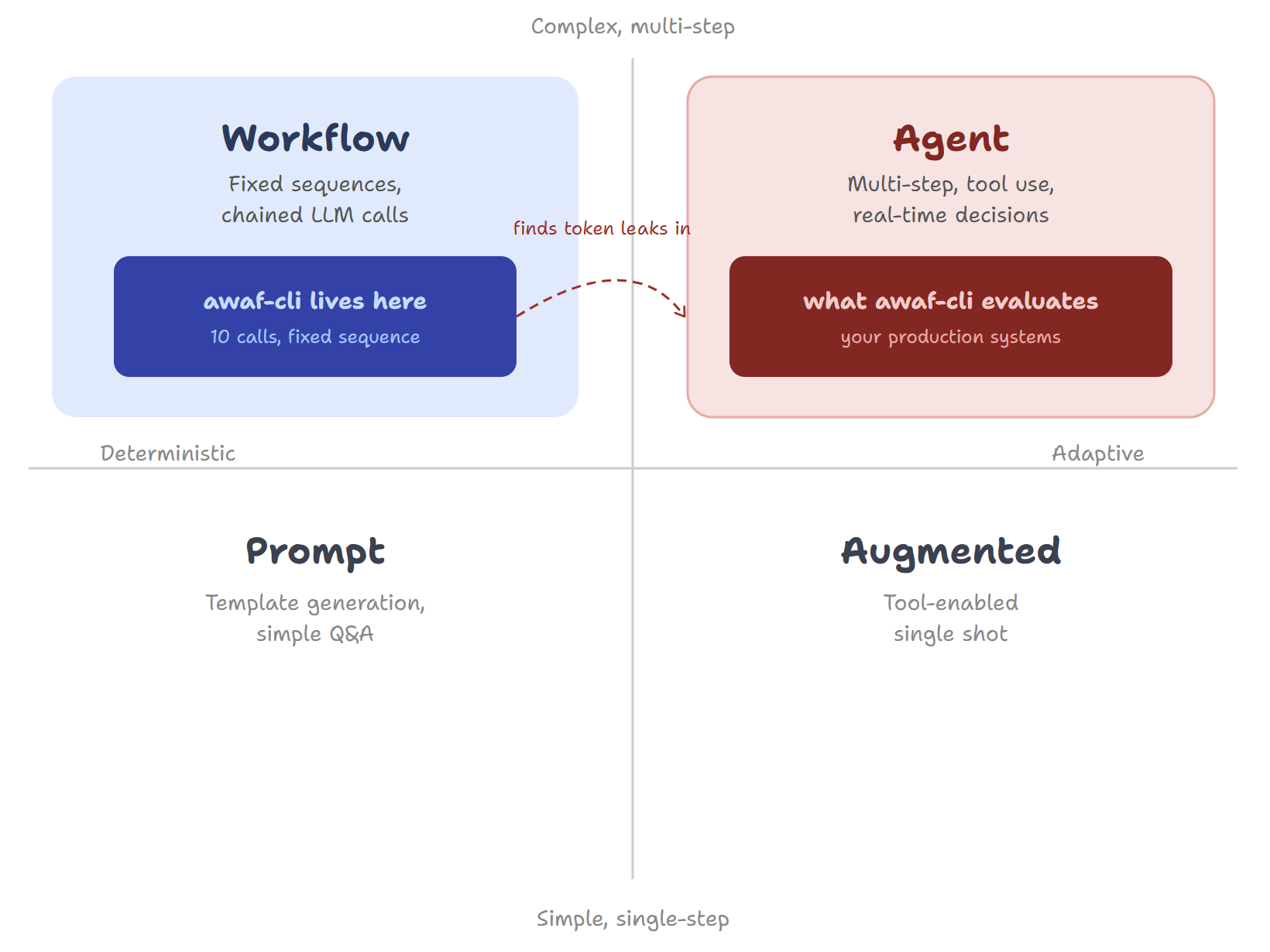
That is intentional. You do not need an agent to evaluate an agent. You need a reliable, repeatable tool that runs the same assessment every time and gives you a consistent score to track. The irony is that awaf-cli found every one of these token problems in itself. A workflow discovering the exact failure patterns that would quietly destroy an agentic system in production.
awaf-cli also asks whether you needed an agent in the first place. The Foundation pillar includes a non-scored advisory that checks your use case against this quadrant. If your system is doing deterministic work, fixed sequences, or single-shot tool calls, awaf will flag it: a Medium finding, severity Caution, noting that a simpler pattern may suffice. Not a penalty. Retrospective guidance. The agent is already built. But now you know.
If these issues exist in a deterministic workflow with 10 fixed LLM calls, imagine what is hiding in your agent that makes real-time decisions across unpredictable tool chains.
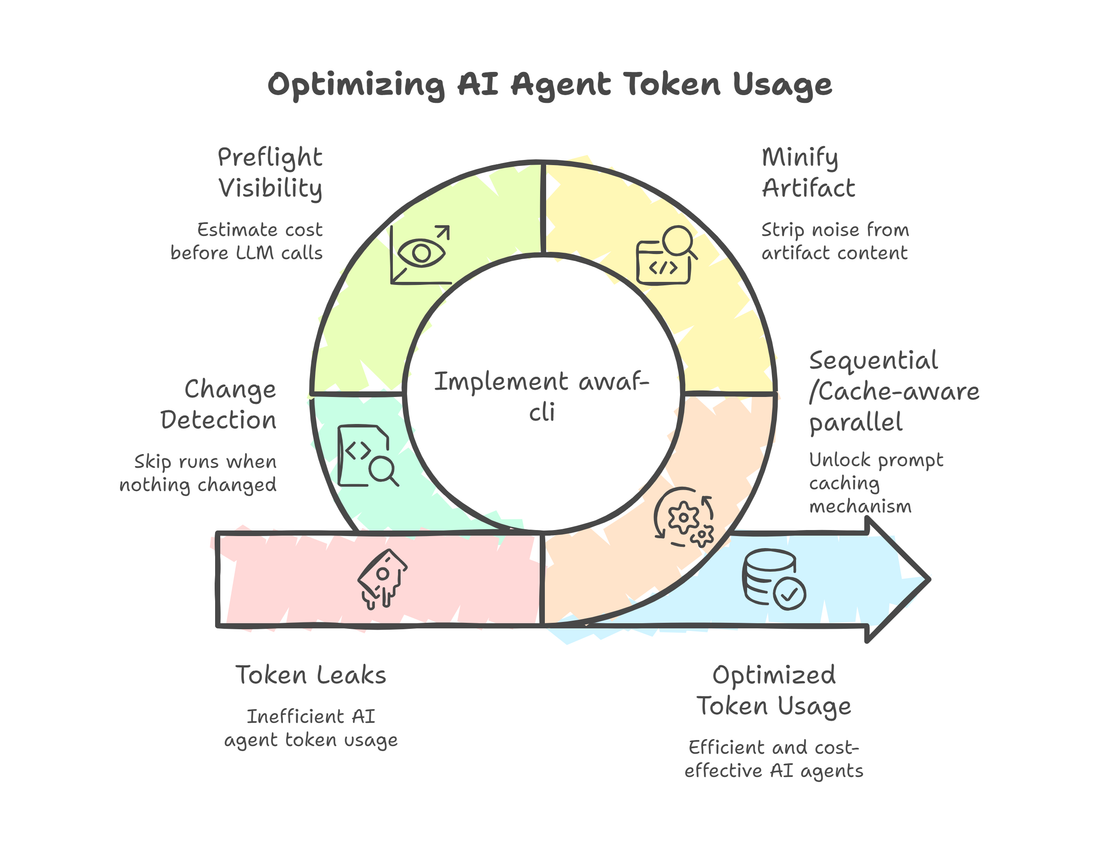
The token problem
awaf-cli makes 10 separate LLM calls, one per pillar. Every single one sends the same artifact content (your codebase) as input. That is 10 x 34,000 tokens of input per run. At full price, every assessment was burning through tokens on the same content over and over.
Four things were wrong:
- The same artifact was being sent 10 times with no caching
- The artifact included noise: blank lines, docstrings, lock files, build artifacts
- There was no visibility into what was being sent or what it would cost until after the bill arrived
- The tool ran even when nothing relevant had changed
Here is how I fixed all four.
Fix 1a: Sequential execution unlocks prompt caching
The artifact content was embedded inside the pillar question in a single user message. Every pillar had a unique prefix, so every call had a unique cache key. The cache was never shared. All 10 calls paid full price.
I separated the artifact into its own cached content block. The pillar question became a second, uncached block. Now the artifact block is byte-identical across all 10 calls.
Call 1 (Foundation): artifact [CACHE WRITE] pays full price
Call 2 (Security): artifact [CACHE READ] pays 10%
Calls 3-10: artifact [CACHE READ] pays 10%
Nine cache hits. Roughly 90% savings on the largest cost center.
Sequential is the default. All 10 pillars run one at a time. Foundation writes the cache, pillars 2 through 10 read from it. ~3.5 minutes wall time. Cheapest option.
Fix 1b: Cache-aware parallel execution
Naive concurrent would fire all 10 calls at once. All 10 would see a cold cache. You would pay full price 10 times and get the speed benefit. A bad trade.
--parallel uses a Foundation-first strategy instead. Foundation runs first and blocks until the cache is written. Then the remaining 9 fire concurrently, all as cache reads at 10%. Wall time drops to roughly 45 seconds. Most of the cost savings stay intact.
The small trade-off: concurrent requests can race slightly on cache timing, which adds a minor token overhead versus pure sequential. If you are on a tight budget, stay sequential. If you need results fast and a few extra cents do not matter, --parallel is the right call.
Fix 2: Minify the artifact before sending
The artifact was full of noise that adds zero architectural signal. Blank lines, decorative comments, Python docstring bodies, 4-space indentation. Lock files, build artifacts, generated code.
I added a minification pass before anything gets sent. Strip the noise, compress the indentation, skip the junk files entirely. Tokens not sent are tokens not paid for. About 15% off every call, including the cache write.
Fix 3: Preflight visibility before any money is spent
There was no way to know what a run would cost until after it finished. I added a preflight check that runs before any LLM call:
PREFLIGHT
Artifacts 12,450 tokens (12 files)
Context window 128,000 tokens (gpt-4o)
Per-pillar est 13,350 tokens (10% of window)
Total est 133,500 tokens (10 pillars x ~13,350)
Cost est ~$0.0093
You see what is going in, how much of the context window you are using, and what it will cost. Before a single call is made. I also cut max_tokens from 4096 to 2048 per pillar call. Pillar responses run 600 to 1000 tokens in practice. Allocating 4096 was waste. The heuristic token counter replaced a per-file API call, which was a pointless network round-trip per file during ingest.
Fix 4: Don't run when nothing relevant changed
The other half of token waste is running when you should not. If the files that actually matter to your agent architecture did not change, the run should skip.
[ci]
enabled = true
schedule = "0 9 * * 1"
change_detection = true
watch_paths = [
"src/agents",
"src/signals",
]
Someone updates a README. awaf does not run. Someone touches src/agents. awaf runs. Your tokens stay where they belong.
Picking the right model
Fix the cost problem first. Then you hit the quality problem.
I ran the same codebase on both Haiku and Sonnet before any of the fixes above:
Haiku (46/100): Six pillars scored exactly 42. "No circuit breaker pattern." "No SLOs defined." Technically true, useless for prioritizing work. Haiku anchors to ~42 when it sees partial evidence. awaf-cli now detects this automatically and flags it as a SUSPECT RESULTS block. Included in the score, marked for review.
Sonnet (70/100 Near Ready): Scores spread across 62 to 78. Findings with addresses: selected = paths[0] in pipeline.py removes the only human checkpoint. _parse_hf_rows raises NotImplementedError unconditionally so the cache is dead code. AWAFMeta hardcodes passed=True, score=100 regardless of what actually happened. Bugs, not observations.
With the caching and minification fixes applied, a 10-pillar sequential run costs roughly 70% less than before the fixes. The cache read price on Anthropic is 10% of the write price. That ratio is what makes the savings stack. Haiku is fine for CI gates and band tracking. Sonnet is what you want when you are building a backlog.
One run is not a point estimate. LLMs are non-deterministic even at temperature=0.0. A score of 72 with a standard deviation of 3 is stable. A score of 72 with a standard deviation of 15 is noise. Run awaf run --runs 3 and you get mean and standard deviation, with suspect flags re-evaluated on the averaged scores.
The bands matter more than the points: Production Ready, Near Ready, Needs Work, High Risk, Not Ready. Moving within a band is noise. Crossing a band boundary is a conversation. If your standard deviation is above 5, skip the absolute threshold and use band regression detection only.
Both models benefit equally from all five fixes. The savings are model-agnostic.
The meta moment
I ran awaf-cli against glitched.sh before any of the fixes. Sonnet found 50+ findings. The report consumed 380,708 input tokens and 18,839 output tokens and still did not finish. Truncated mid-finding.
The tool built to surface agentic system failures surfaced its own. Hardcoded scores. Dead cache paths. A human approval gate that was quietly removed. I did not know any of it until I ran the assessment.
Now imagine that codebase is not a side project. It is your bank's loan decisioning pipeline. Your insurance claims processor. Your healthcare triage system. The agents are running. The logs look fine. Nobody knows AWAFMeta is returning passed=True, score=100 on every call regardless of what actually happened inside.
That is not a hypothetical. That is what no architectural visibility looks like in production.
What happened after the fixes
Same codebase. Same model.
Before: 70/100 Needs Work. 29 High findings. Assessment truncated.
After: 89/100 Production Ready. Score jumped two bands. Foundation at 90, Cost Optimization at 100 verified, Reasoning Integrity at 91 verified. The remaining gaps are real and named: budget counter resets on restart, checkpoint store is not persisted, eval scheduling is documented but not wired. Known issues. Work to do.
On a stable codebase the following week, calls 2 through 10 hit the cache. The cost drops further.
One note on the SKILL vs CLI
awaf exists in two forms. The CLI (pip install awaf) runs automated assessments against your codebase. The Claude Code Skill runs dialogue-driven assessments in Claude Code, accepting code, docs, observability exports, runbooks, or verbal descriptions. The SKILL references AWAF v1.0 scoring bands (Production Ready at 90+). The CLI is on v1.3 (Production Ready at 85+). If you are comparing scores across both, use the band label not the number.
Commit reference
- Caching fix (artifact as separate cached block):
de82dcd - Ingestor minification (~15% token reduction):
03a04b0 - Sequential default +
--parallelFoundation-first:6ad3bb1,fd5c295 - Preflight cache-aware cost estimation:
9bf7a13 - max_tokens 4096 to 2048 + heuristic token counter:
2f11db8 - SCOPE rule in pillar prompts (cross-pillar bleed fix):
8241736
These commits are found in history of awaf-cli.
awaf-cli is open source at github.com/YogirajA/awaf-cli. The AWAF framework specification lives at aradhye.com. The canonical home for the framework is awaf.ai.



Comments