
When the world wide web first emerged, integrating different types of operating systems was a core challenge. Hypertext transfer protocol (HTTP) created communication channels by sharing hypertext, these systems started speaking a common language over an accepted protocol, and the internet as we know today was born.
When creating a microservices architecture, the integration challenges are not very different: Multiple implementation technologies are physically separated by a network and need to communicate with each other. Microservices integration plays a vital role in creating a seamless experience of the system, from the end user’s perspective. Correctly integrated systems also help realize the benefits of distributed systems: They enable scaling at the service level and improve efficiency, and have a potential of reducing the infrastructure costs while serving business needs [1].
On the other hand, incorrectly integrated systems completely undermine the benefits of a microservices architecture: It can result in painful data loss and integrity issues. The problems are usually very hard to track down, and in the meantime, users are impacted adversely.
Seamless integration depends on a number of considerations, which we looked at in our previous post, Principles for Microservices Integration. These serve as a guide to choosing the type of integration that will offer the most autonomy and scale. We’ll cover the various options and their pros and cons below.
Database Integration
In this pattern, two or more services read and write data out of one central data store. All of the services go to this central data store. We can illustrate this using the banking application example from our previous post, which takes login, user profile, transactions, notifications, credit score, and spending reports as separate services defined by the business functionalities.
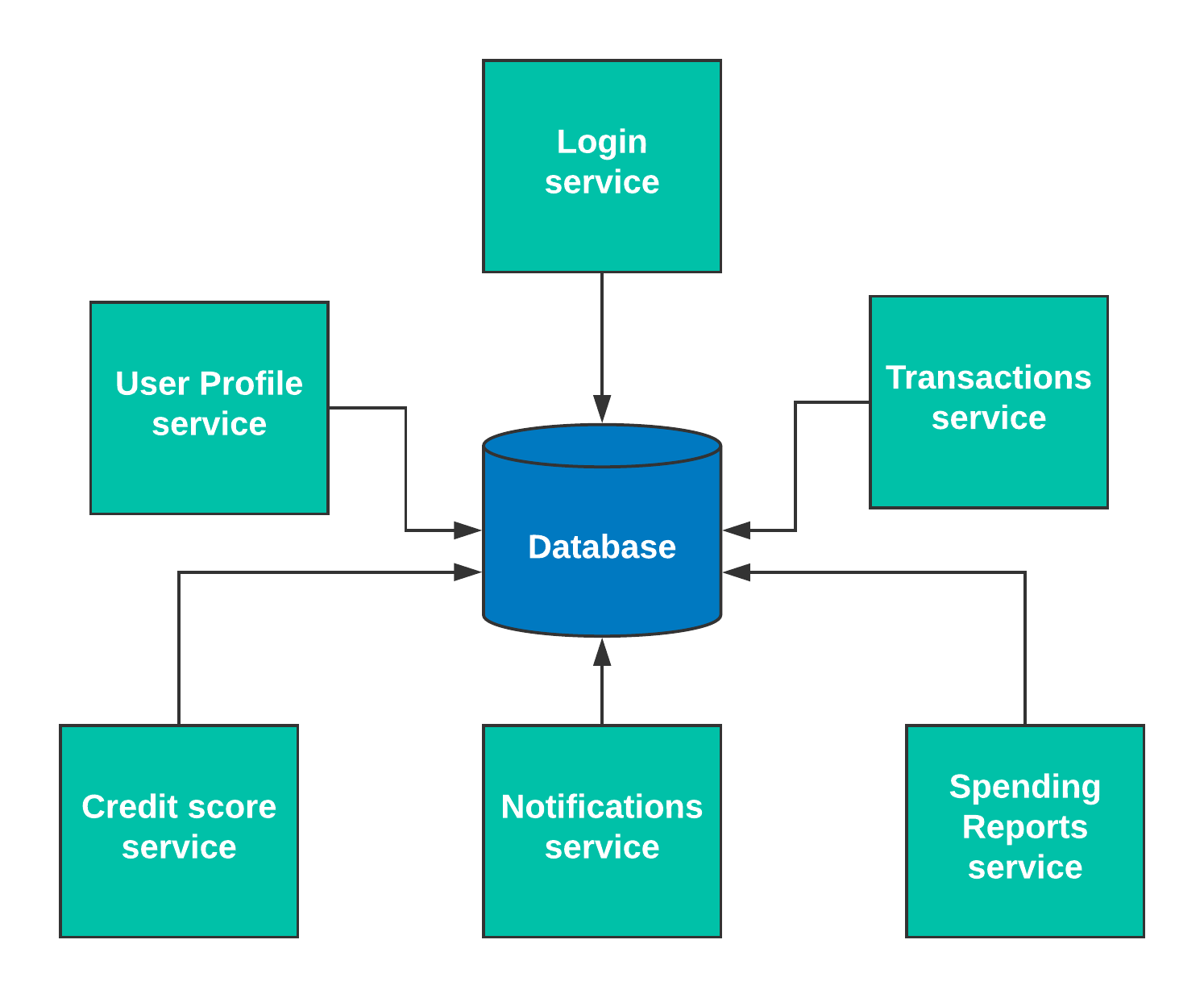
One of the significant advantages of database integration is simplicity. The transaction management is more straightforward as compared to other patterns. This is perhaps the most widely-used pattern of integration—but also the most abused.
This pattern couples services together undesirably, making the microservices architecture more difficult to change and expensive to scale. Defining the data ownership and updating the schema can become a messy process—every change requires re-compiling and deploying all of the services. It pushes towards highly orchestrated, big bang style deployments. This type of integration can create significant obstacles in maintaining the autonomy of microservices.
Under the needs of high scale, the only option is to throw more hardware at the database, and even then it becomes difficult to avoid deadlocks in the database and row-level contentions.
Ideally, we don’t recommend this pattern for inter-services communication. It can be used in one of the early phases of a phased microservices rollout. In other words: If you use it, lose it soon.
Synchronous API calls
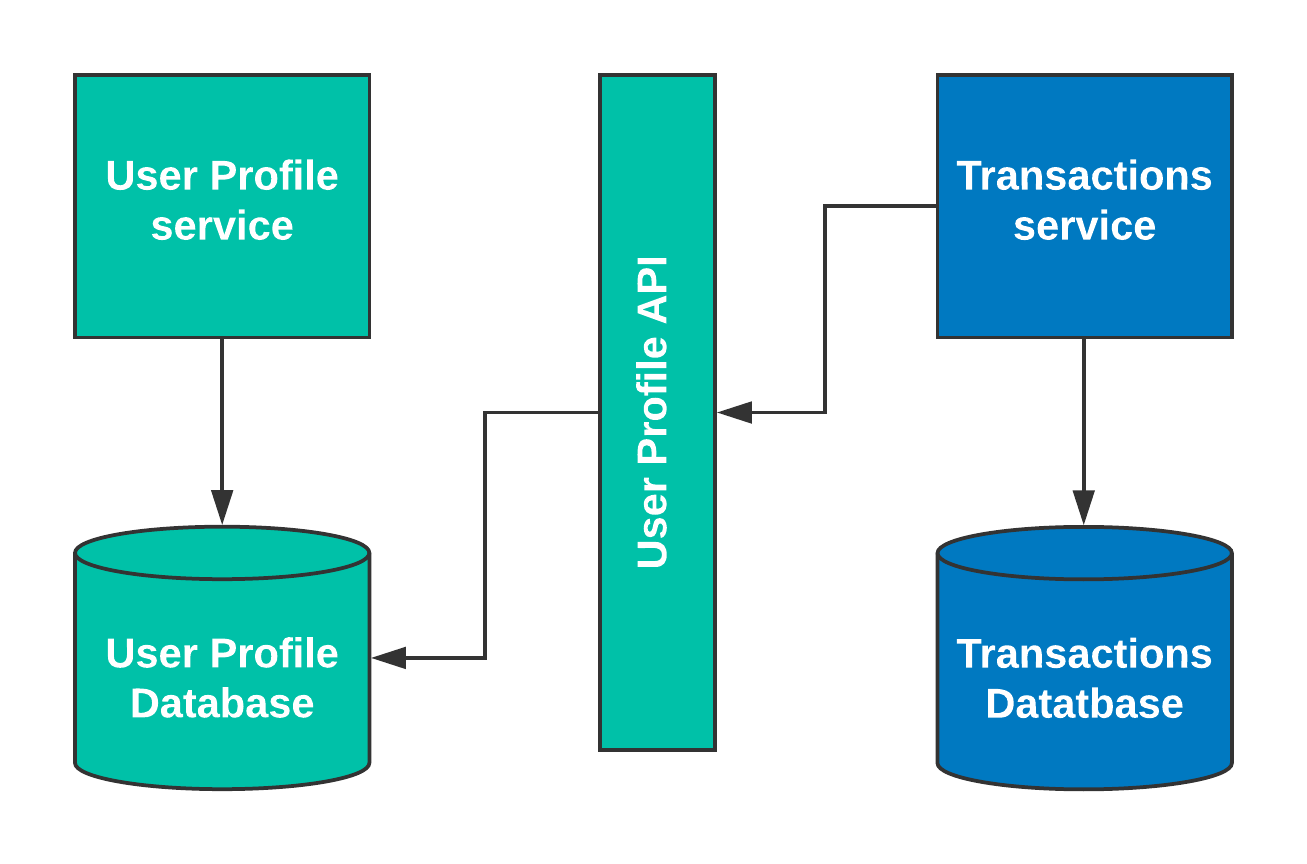
In this integration pattern, the services communicate synchronously through an API. All the access to each other’s data is coordinated through an API in a request-response fashion, and the service waits for data from the API to perform its action. In the example above, if the transaction service needs to read the user profile data, it calls the user profile API and gets what it needs.
This provides a decent abstraction over a direct database call and offers excellent flexibility in terms of technical choices. This provides the benefit of hiding many implementation details: The abstraction gives us the freedom to change technologies without affecting our clients. For example, the user profile service could use JAVA and MySQL, while the transaction service could use SQL server and .NET, and they can still easily speak to each other through the API.
However, this is not much different than the direct database integration pattern. Adding another network hop on top of a database call can also inhibit scale: by increasing the workload, performance decreases—it is significantly at odds with most of distributed systems fallacies [2]. This integration pattern also makes transaction management difficult and inhibits autonomy, as services depend on one another’s uptimes. In microservices, if you have to read data synchronously outside of your system boundary, that is a service-oriented architecture smell [3].
In some cases, this integration pattern is the best or unavoidable. Security tokens are a prime use case for synchronous API integration because those tokens are short-lived and can’t be generated before they are required. Synchronous API calls should be used sparingly, if possible. If used, they should be versioned and should be used with a circuit breaking mechanism such as Polly [4].
ETL (Extract, Transform, and Load)
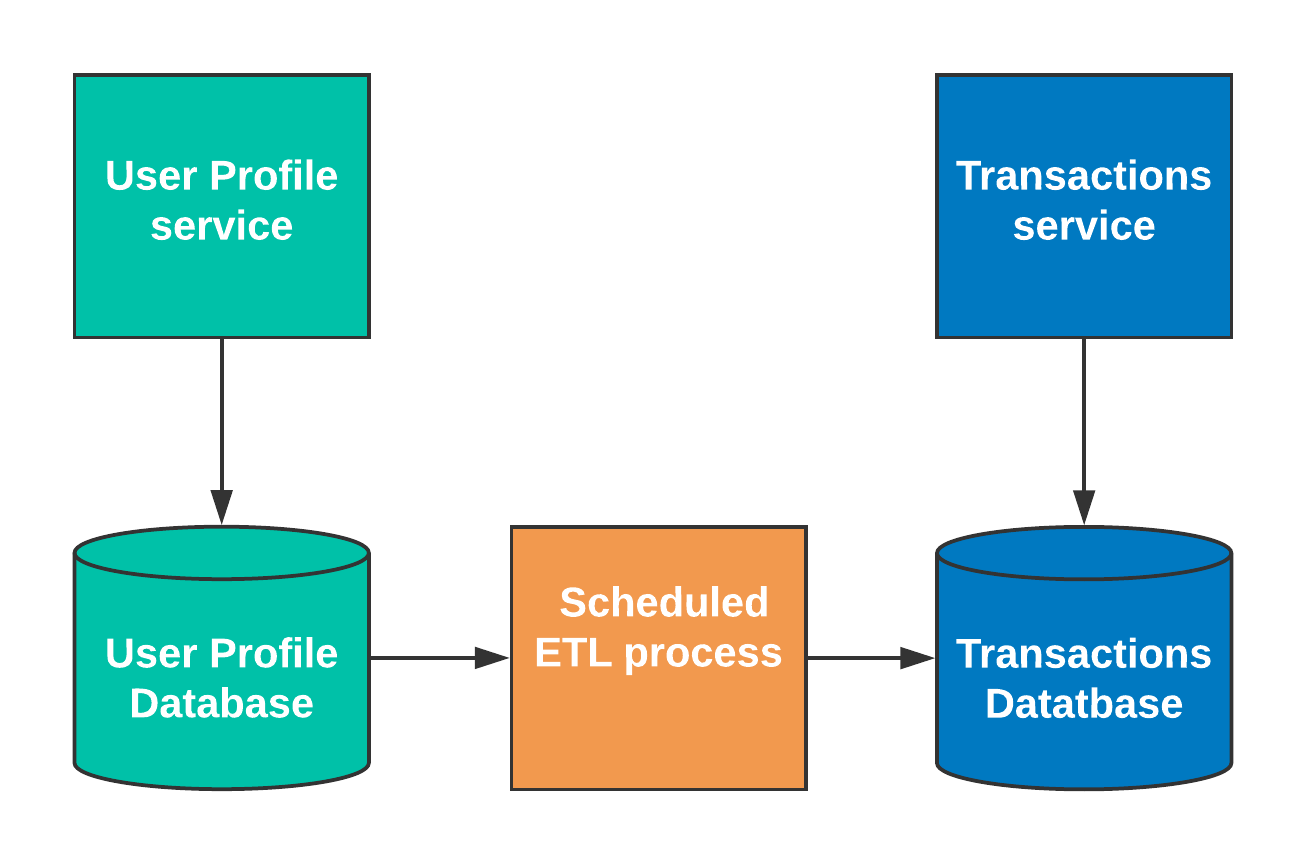
ETL entails synchronizing data via background processes on a predefined schedule. This data can be pushed or pulled. Only backend ETL processes need database access. It is asynchronous, meaning services can execute without waiting for a “callback.”
This integration pattern also hides implementation details nicely. It provides reasonable decoupling because the services are not dependent upon one another’s uptimes. Live users don’t get affected by the uptimes or the processing time.
The ETL processes have to change with the source and destination databases. With ETL integrations, data consistency depends on the schedule and duration. Figuring out the change delta could get too complicated. In these situations, the teams fall back on pushing the entire dataset out. That makes processes very long-running, significantly undermining their usefulness.
Reporting services are a natural fit for this type of integration. These processes have their place but usually get very involved with time. They should be used only when the stale data is acceptable in the system.
Messaging
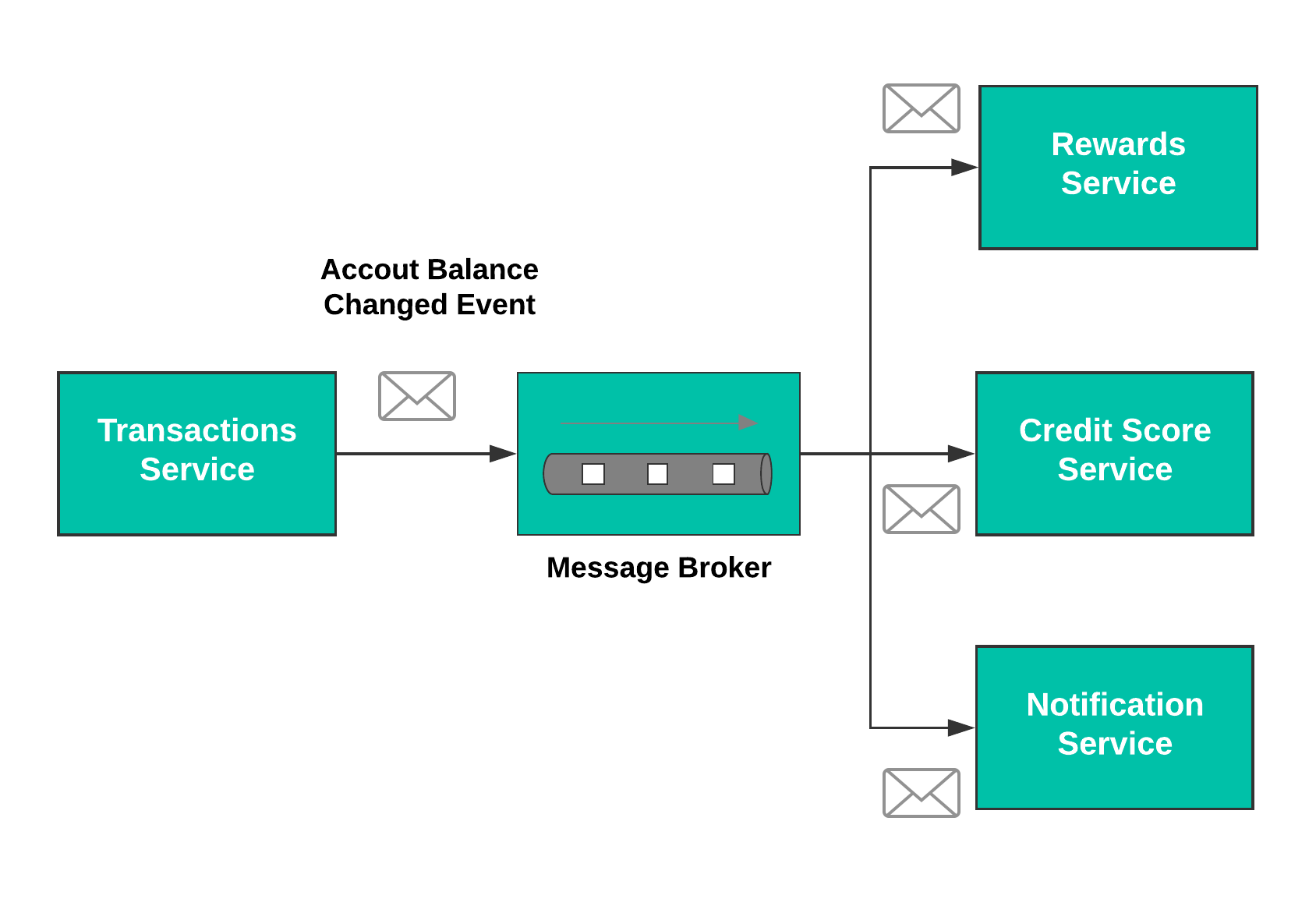
In this pattern, services exchange meaningful messages with each other through what are called commands or integration events. They are sent over message transports such as RabbitMQs, MSMQs, or Azure Service Bus. In the example above, the transactions service generates an “account balance changed” event and puts it on a message broker. The rewards service, credit score service, and notification service each subscribe to that event and react to it as necessary. This is a publish-subscribe pattern, and there are plenty of other useful patterns for messaging. Enterprise Integration Patterns is an excellent resource for learning more [5].
If done correctly, messaging provides very good decoupling. It offers complete flexibility in terms of technology choices, as long as they can communicate correctly with the transport. Pushing data to subscribers makes the sending part simpler, and the sender remains completely unaffected by the processing details on the subscriber’s side.
Incorrect service or transaction boundaries can complicate messaging implementations. Also, the loose coupling this pattern provides can come at the cost of consistency. It requires a high level of discipline to implement messaging correctly, and inexperienced teams may struggle with it.
Two categories of messaging
Typical messaging solutions are built on top of the properties of the transport. At a high level, these transports could be divided into two categories: message queueing and message streaming.
The queueing solution involves dealing with live data. Once a message is processed successfully, it is off the queue. As long the processing can keep up, the queues won’t build up and won’t require too much space. However, the message ordering can’t be guaranteed in cases of scaled-out subscribers.
When a new subscriber comes up, we have to involve the source to bring it up to speed. They need specific migration path, which could be challenging depending on the scale and the business domain.
In the streaming solution, the messages are stored on a stream as they come in order. That happens on the message transport itself. The subscriber's position on a stream is maintained on the transport. It can reverse forward on the stream as necessary. This is very advantageous for failure and new subscription scenarios. However, this depends on how long the stream is. It requires a lot more configuration from storage perspectives, necessitating the archiving of streams. Azure Event Hubs and Kafka are some of the examples of this. Some databases such as Cassandra support generating events out of transaction log. Kafka is often looked at as a direct replacement of the ETL jobs [6].
The typical use cases here assume that the system is able to work with somewhat stale data. If that’s not the case, we need to analyze the business domain a bit more and understand why. In our example, when the transaction update happens, the credit score update doesn’t necessarily need to happen in a real time. Messaging fits very well here. We can set the user’s expectation accordingly and allow the services to manage their own load.
Parting thoughts
Every microservices architecture will be different, and there are no perfectly prescribed solutions for integration. We need to keep failure scenarios in mind when we use them—that drives to a combination of these integration patterns. For example, Netflix uses messaging to move the data and they fall back synchronous API if messaging is not available or data is still in transit [7]. In each case, the ideal is achieving the most flexible and scalable microservices architecture—but you have to consider the implementation details and your own capabilities first. The chart below shows how some integration patterns are more desirable from a microservices standpoint, but inherit complexities that your development team must be prepared to deal with:
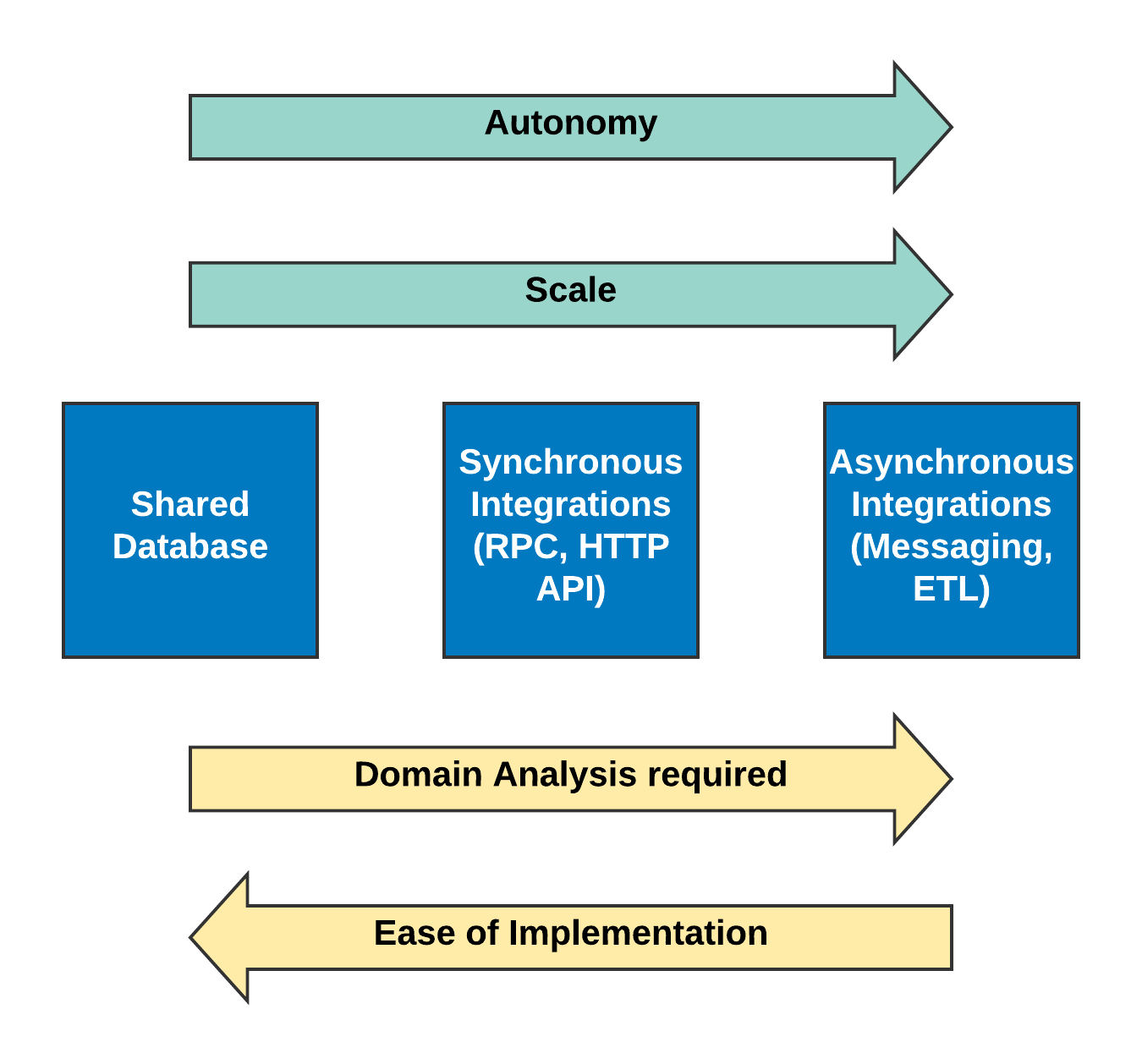
The key takeaway here is to have asynchronous patterns when needed for scale and autonomy. To achieve this, you need solid service boundaries and clear data ownership. Otherwise, you end up with complex and unsustainable integration scenarios. Modeling the business processes is important. That will let you know which use cases and processes are inherently asynchronous and suitable for messaging. How do we model the business processes and define the boundaries? We will look into that in the future posts.
References
[1] – Microsoft .NET Microservices Architecture E-book
[2] – Fallacies of Distributed Computing
[3] – What are Microservices?
[4] – The Polly Project
[5] – Enterprise Integration Patterns
[6] – ETL is dead
[7] – Mastering Chaos at Netflix


Comments