
In a previous post on microservices integration patterns, we talked briefly about messaging. Messaging comes with many options and patterns, and one of the most critical decisions you’ll make is choosing between message brokers. RabbitMQ and Kafka are lead options, seen as representing queueing and streaming, respectively. If you search for a comparison between the two, you are unlikely to get an unbiased view: Vendors on both sides have muddied the internet with praise of their preferred tool. The answers are hardly a slam dunk as some posts or talks seem to suggest. In many of our clients’ experience, choosing the wrong option only brings on more problems. So, how do you make the right choice? Instead of providing a prescriptive answer, we’ll look at the evaluation criteria and provide a decision matrix that you can use to arrive at the right solution for your unique situation.
How does RabbitMQ work?
RabbitMQ is an implementation of Advanced Message Queuing Protocol. It brings in concepts for the advanced routing of messages such as Topic, Direct, and Fanout exchanges. These exchanges are bound to subscriber queues.
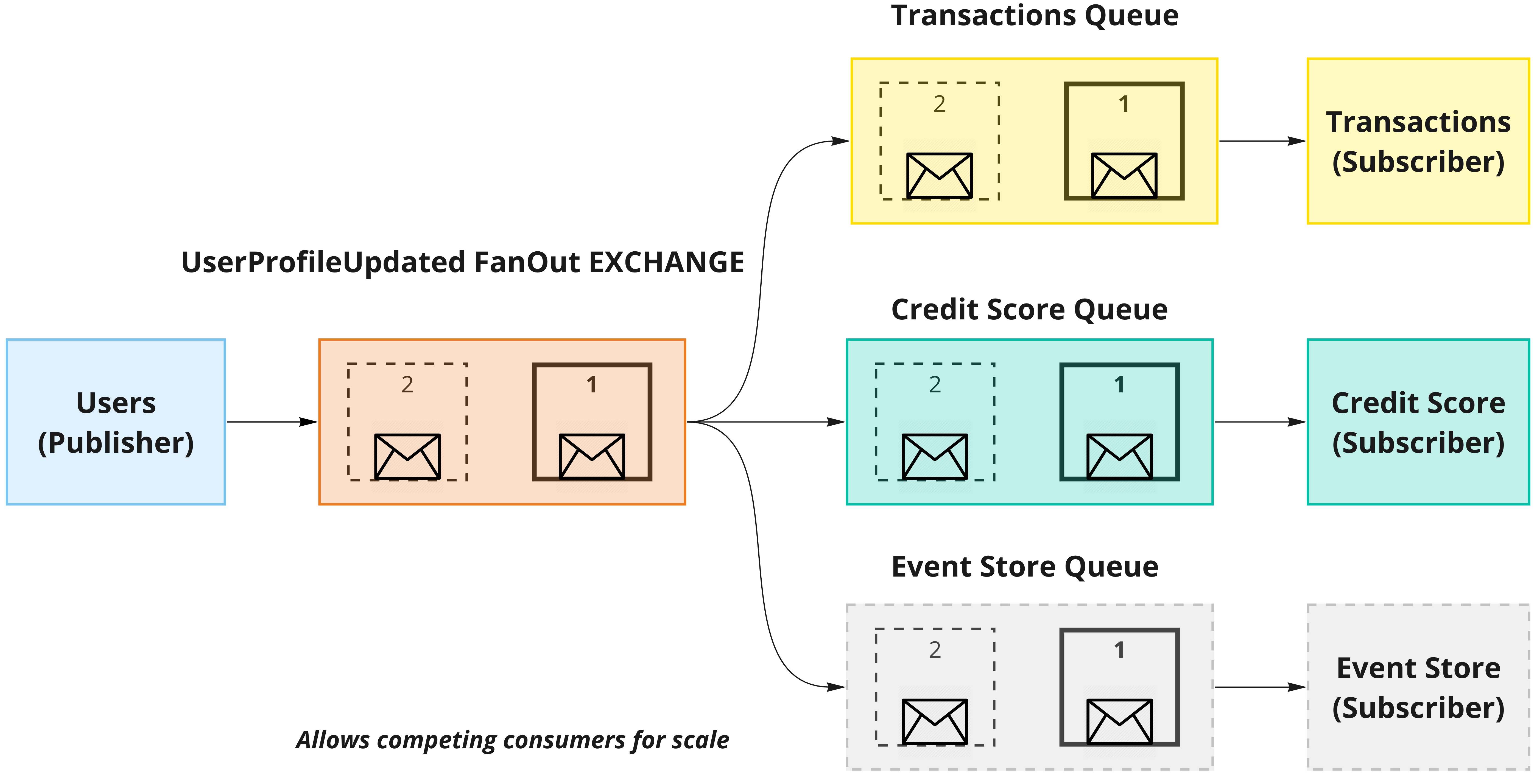
In the diagram above, we have a publisher, the Users service, with the intention of generating a UserProfileUpdated event. It is bound to the UserProfileUpdated FanOut exchange. There are two subscribers to this exchange: the Transactions and Credit Score services. When they start up and indicate the intention of subscribing to this event, binding is made with the exchange. After that, when the publisher sends an event to the exchange, RabbitMQ delivers the event to all bound queues in the order that it was received. Each bound queue gets its copy. The event doesn’t get dequeued until those subscribers send a positive acknowledgment to their respective queues. We can easily add another subscriber to this and store these events in an Event Store if needed. Repeated failure to handle these messages by the subscriber can be moved to another exchange, named a dead letter exchange. The dead letter exchange could be managed separately. We can achieve high throughput by adding multiple competing consumers to the same queue and managing the routing.
How does Kafka work?
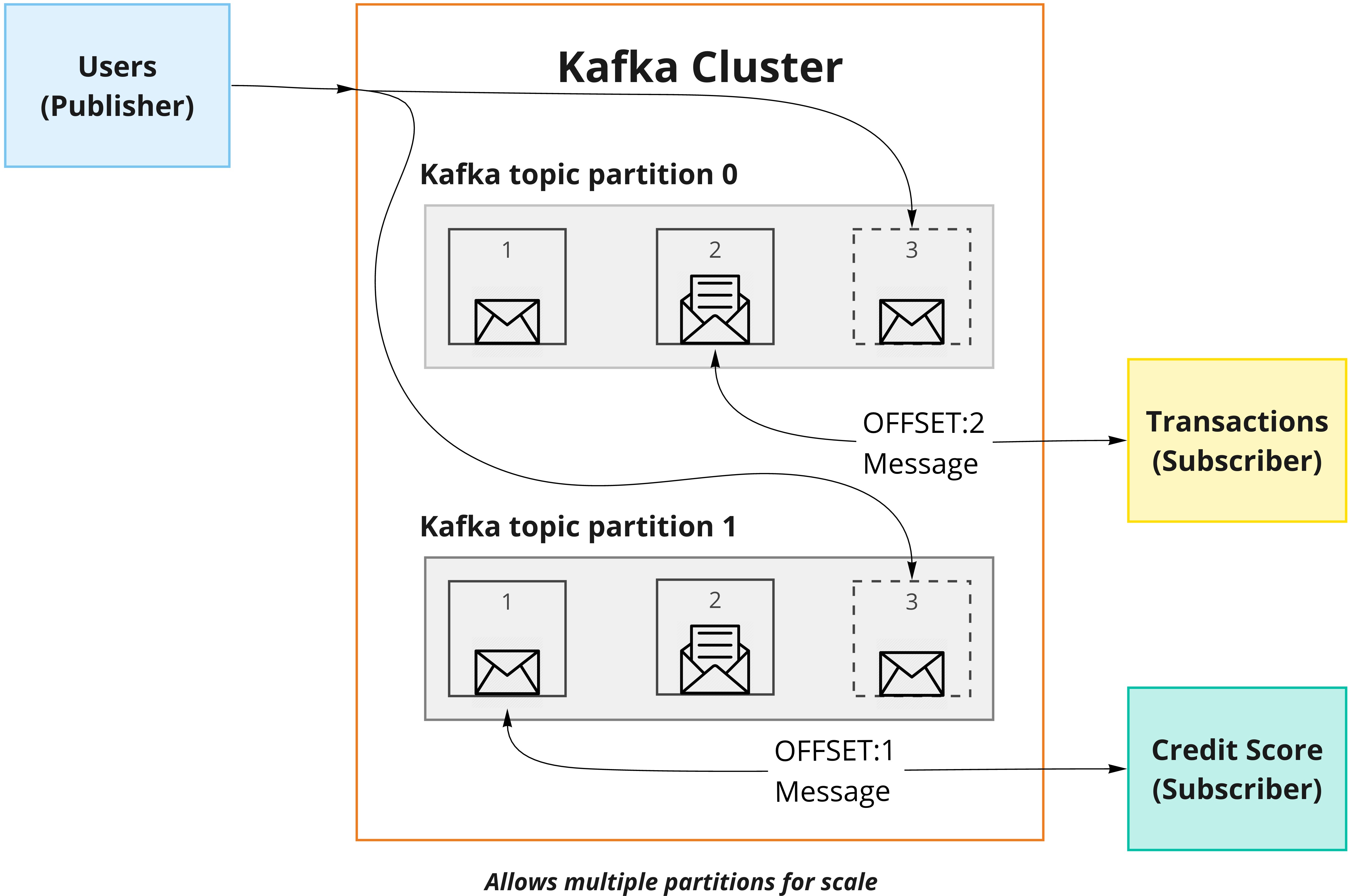
This diagram represents the same scenario implemented in Kafka. Kafka is an event log: When the Publisher (the Users service) sends an event, it simply gets appended to a stream, similar to how a log entry would be made. The consumers pick up messages from their specific position (offset) in the stream and consume everything afterward sequentially. The diagram above shows the Transaction service’s offset is 2, so it gets an event sitting at that position and continues. The Credit Score service’s offset is 1, so it picks up that message and continues. This way, consumers can freely move back and forth as needed. The events are never taken off the stream. The amount of time for which an event should be in the stream is configurable. If a consumer fails to process any event, it can easily consume that event again. Each consumer gets its own partition. Multiple consumers are not allowed for a partition. The degree of parallelism is controlled by the number of partitions. This is how Kafka can support large volumes of data. The delivery of messages to these partitions is handled by Kafka. The consumers are completely unaware of the internal routing and related intricacies.
Now that we see what a typical publish-subscribe with events looks like in both Kafka and RabbitMQ, let’s compare some high-level features.
How do they compare head to head?
- RabbitMQ cannot be used as a store; Kafka can.
- In RabbitMQ, ordering is not guaranteed once we have multiple consumers. Kafka guarantees order for a partition in a topic.
- Messages can’t be replayed by RabbitMQ—they have to be resent those from the sending side. We do this with the Message Outbox pattern. Kafka stores data in the order it comes in and supports message replay with the help of offsets. However, it introduces other tradeoffs around data compaction, how long to keep the data on the streams, what to do if data required predates the stream, etc.
- RabbitMQ doesn’t support transactions natively, it uses acknowledgments. Kafka supports transactions.
- RabbitMQ has great .NET support—it completely outshines Kafka in this regard. Kafka treats .NET support as a secondary priority.
- RabbitMQ has good tooling for management on Windows. Kafka does not.
- RabbitMQ implements the Advanced Message Queuing Protocol. These guardrails help you stumble into a pit of success. With Kafka, you will have to implement a lot of these patterns and disciplines yourself.
- RabbitMQ doesn’t need an outside process running. Kafka requires Zookeeper’s running instance for its broker management. Zookeeper is responsible for assigning a broker for the topic.
- Out of the box, RabbitMQ is behind in multithreading support compared to Kafka—but not by much. Since NServiceBus works with RabbitMQ and has good support for multithreading, it is lesser of a problem for RabbitMQ. In both worlds, ordering is not guaranteed if the consumers are scaled out or have fetching records using multiple threads.
- RabbitMQ has a lot of plugins to support your needs. Kafka is not as mature and therefore doesn’t have as many plugin options.
There are a lot of features to compare, and baking these into an overall decision can be challenging. The evaluation criteria we’ve developed can help you weigh the options, together, and end up with an empirical answer.
How do you choose one, or both?
As Caitie McCaffrey, one of the most well known Distributed Systems architects puts it in this tweet, there can only be trade-offs within different contexts. Building a scoring sheet can help you evaluate your options. The considerations you choose will vary in different contexts, research, and comfort levels. Below is an example of an actual evaluation that we performed. You assign a “1” to the tool that is stronger in each scenario. If neither outranks the other, you assign “0”s to both. Tabulating the totals will give you an idea of how one suits your needs over the other.
Sample Scoring Sheet
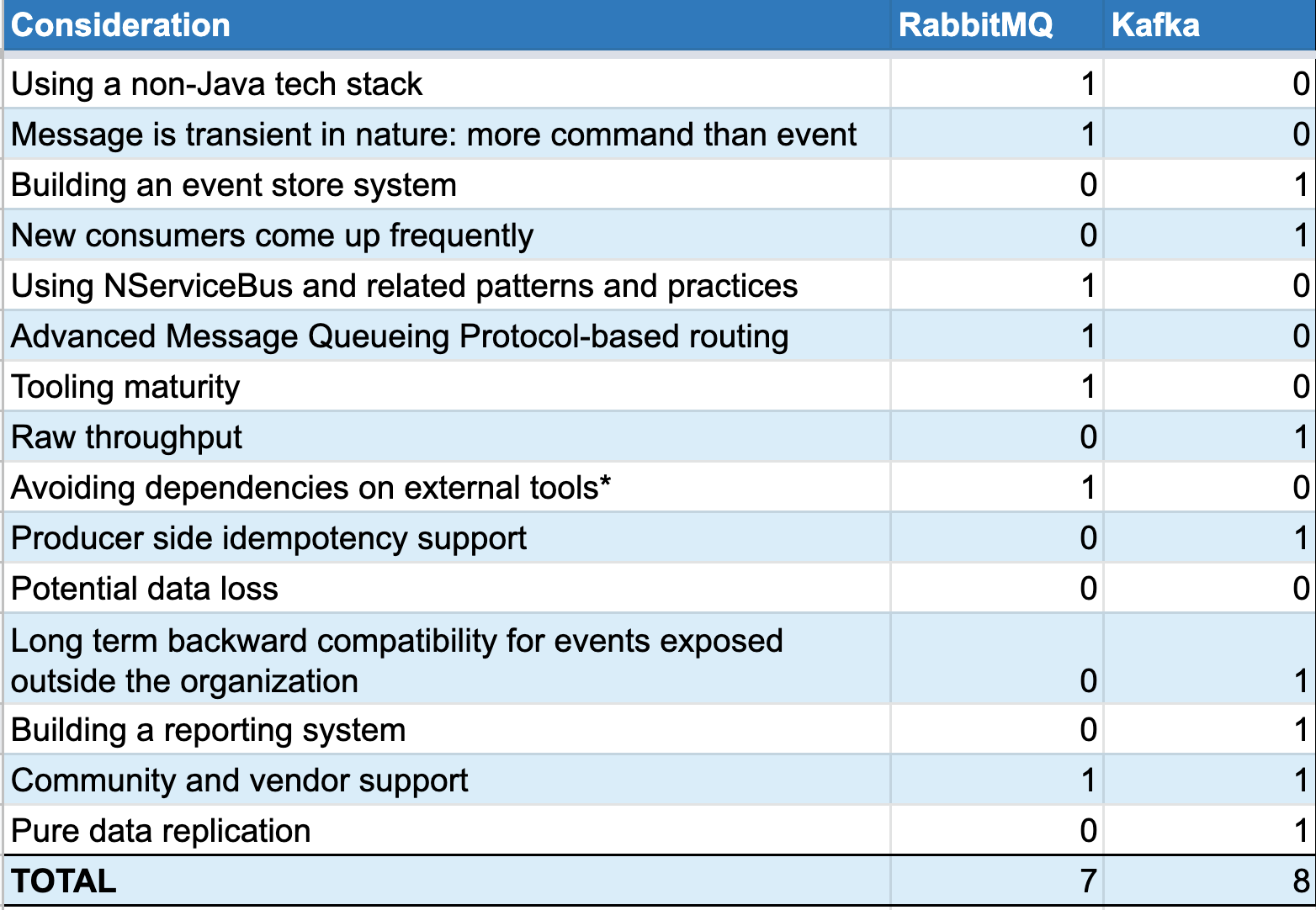
*Kafka requires a dependency on Zookeeper
As this case demonstrates, there may not always be a clear winner: but using both or transitioning can help you cover all of your bases. If you’re leaning towards having both in the environment or introducing Kafka slowly, you can make use of a connector between RabbitMQ and Kafka.
When you choose these tools, you also need to be cognizant of some manual enhancements you may need to do to make them more developer-friendly. For example, if you choose RabbitMQ and still need the Event Store, you will need to build message handlers to populate the store. Similarly, if you choose Kafka and you need process management, you will have to do extra work, perhaps in a homegrown library to support that. Accounting for extra work like this will better ensure you make the correct decision.
Have you answered these prerequisite questions?
Any tool or framework may not necessarily address all underlying architectural problems. If database integration was the norm in the past, the chance of repeating mistakes is high. We need to think differently when we are dealing with tools like Kafka. For example, we don’t necessarily need new topics per message type, as Martin Kleppmann points out in his event types for Kafka topic post.
A change in mindset starts with the questions below—they need to be answered before you implement either tool. This is just a starting point, but if these considerations are not addressed early on, the odds of messaging success will be against you.
- Do you have observability/monitoring in place? Can you demonstrate a need for scale?
- Have you answered underlying architectural concerns in your system?
- Do you have proper business and data boundaries in place?
- Do you have a regular check of the business and data boundaries process?
- Do you have operational and standards concerned answered? Is your choice compliant with them?
- Have you documented your hardware constraints? Is your choice compliant with them?
- Have you documented your security constraints? Is your choice compliant with them?
- Have you evaluated other platform as a service (Event Hubs on Azure) options?
- Have you implemented the Outbox pattern correctly? Data loss is possible with RabbitMQ and Kafka both.
Parting thoughts
Both RabbitMQ and Kafka are powerful tools, but you need to be able to evaluate them objectively per your needs. Instead of making a “gut choice,” be a little more data-driven in your evaluation. The criteria you apply may vary depending on the context, and that is to be expected. Controlled consideration will represent the reality a lot more closely than the vendors of these tools can.
References
Advanced Message Queuing Protocol: https://en.wikipedia.org/wiki/Advanced_Message_Queuing_Protocol
Dead Letter Exchange: https://www.rabbitmq.com/dlx.html
Message Outbox: http://gistlabs.com/2014/05/the-outbox/
The .NET client for Kafka is behind https://github.com/confluentinc/confluent-kafka-dotnet/issues/34
High throughput can be achieved with both tools. Some easily available benchmarks for these tools are here: https://engineering.linkedin.com/kafka/benchmarking-apache-kafka-2-million-writes-second-three-cheap-machines
https://docs.openstack.org/developer/performance-docs/test_results/mq/rabbitmq/cmsm/index.html
Producer Side Idempotency:
https://www.confluent.io/blog/exactly-once-semantics-are-possible-heres-how-apache-kafka-does-it/
https://kafka.apache.org/documentation/#upgrade_11_exactly_once_semantics
Kafka can lose data too: https://www.slideshare.net/JayeshThakrar/kafka-68540012
Martin Kleppman’s talk on Kafka: https://www.youtube.com/watch?v=avi-TZI9t2I
Kafka/RabbitMQ connector: https://www.confluent.io/connector/kafka-connect-rabbitmq/
My past posts on observability: /tag/observability/
Kafka documentation on Zookeeper: https://kafka.apache.org/10/documentation.html#zk
Nice blog post series on Kafka vs RabbitMQ comparison: https://jack-vanlightly.com/blog/2017/12/4/rabbitmq-vs-kafka-part-1-messaging-topologies


Comments